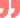

“關于是否需要做預測的事情在上一篇文章《聊一下供應鏈需求預測》,已經很清楚的說明了是需要的,那么我們在日常的工作中如何去做呢?其實沒那么高深,本文就說說利用excel做簡單的需求預測。”
—— 供應鏈日常
所有預測都是錯的,但準確度高和低還是不一樣的
黃雪川,公眾號:供應鏈日常聊一下供應鏈需求預測
我們通常說的這個人靠不靠譜?是通過之前他說的和他做的是否一致來判斷的。一個產品的預測是否靠譜,我們也可以通過看它的歷史預測和實際生產/出貨的差異來判斷。在統計學中有這么一個衡量方法叫MAPE,平均絕對百分比誤差(Mean Absolute Percentage Error)

MAPE取值的范圍[0,+∞),MAPE 為0%表示完美模型,MAPE 大于 100 %則表示劣質模型。注意:當真實值有數據等于0時,存在分母為0的問題,該公式不可用!我們看一個示例:這個產品從4月到9月的MAPE為15.1%,還算靠譜的預測,

回歸分析(Regression):確定兩種或兩種以上變量間相關關系的一種統計分析方法。通過數據間相關性分析的研究,進一步建立自變量(i=1,2,3,…)與因變量Y之間的回歸函數關系,即回歸分析模型,從而預測數據的發展趨勢。
來源:網絡
說起預測分析,很多人會想到大數據、AI算法、Tableau、python等等,其實在真實的工作中沒那么復雜,也用不到那么高大上的工具和方法哈,最基本的就是使用Excel數據分析工具中的回歸分析就可以了。如何做呢?我們來看一個例子。

一條汽車生產線,共線生產兩種車型A5和B7,有一種A5車型專用長周期物料,必須提前做預測。我們先看看歷史數據:

我們利用前面4個月的實際生產數據來做多元線性回歸分析,生產天數作為變量X1,全月總量作為X2,車型A5作為目標Y。我們來看看知道下月生產天數和總的預計產量的情況下,我們如何預測A5車型的量。回歸分析后的結果如下:

幾乎所有的回歸模型的軟件,最終都會給出參數的顯著性檢驗,一般我們只需要理解:
回歸統計表:Multiple R即相關系數R的值,大于0.8表示強正相關;R Square是R平方值,又叫判定系數、擬合優度,取值范圍是[0,1]。R平方值越大,表示模型擬合得越好。一般>70%就算擬合得不錯,60%以下的就需要修正模型。這個案例里R平方0.98,還算相當不錯;Adjusted R是調整后的R方,這個值是用來修正因自變量個數增加而導致模型擬合效果過高的情況,多用于衡量多重線性回歸。
方差分析:df是自由度,SS是平方和,MS是均方,F是F統計量,Significance F是回歸方程總體的顯著性檢驗,這是我們比較關注的,F檢驗主要是檢驗因變量與自變量之間的線性關系是否顯著,用線性模型來描述他們之間的關系是否恰當,越小越顯著。殘差是實際值與預測值之間的差,殘差圖用于回歸診斷,回歸模型在理想條件下的殘差圖是服從正態分布的。
第三張表重點關注P-value,也就是P值,用來檢驗回歸方程系數的顯著性,又叫T檢驗,是在顯著性水平α(常用取值0.01或0.05)下F的臨界值,一般以此來衡量檢驗結果是否具有顯著性,如果P值>0.05,則結果不具有顯著的統計學意義,如果0.01<p值<0.05,則結果具有顯著的統計學意義,如果p<=0.01,則結果具有極其顯著的統計學意義。t檢驗是看某一個自變量對于因變量的線性顯著性,如果該自變量不顯著,則可以從模型中剔除。< p="">
第三張表第一列我們可以得到此例的回歸模型方程(參數取1位小數):
Y= -213.1+61.5X1+0.6X2
我們就可以利用這個方程來預測一下5月的A5車型需求了,我們看看這個結果,可以看到還是比較準的:

既然所有預測都是錯的,那么就一定有糾偏的過程。不管你用什么軟件,最終的預測都不是100%準確的。對于這個偏差的態度,很大程度上決定了一家公司供應鏈協同的水平。比較常見的三種極端:
1.躺平:銷售你說是多少就是多少,我也不做預測也不做考核,反正當二傳手,銷售報過來的數據就原封不動轉給供應商,多了少了,都和我沒關系;這樣可是苦了很多供應商,一但出大問題其實你的交付也成問題,最終客戶利用受損,公司也自然不要想賺錢了;
2.內卷:對銷售的預測數據做KPI考核,非得想辦法搞得你難受,反正預測不準我難受了,你也不得好受。但大家都知道,很多事情一旦考核就會造成人們行為變形。為提高預測準確性,時間越靠近就越準,銷售通常會拖到最后時刻才給數據,這對較長的供應鏈也是沒有好處的。預測準了,物料還是供應不上;
3.擺爛:老子就是硬,不管你什么銷售預測,我說是多少就是多少,多了我沒有,少了你也得接受。誰叫你預測不準呢?
看了上面幾條估計有人都在樂了,在現實生產中這樣的狗血事件太多了。其實都不好,我們要"看清生活的真相,還依然熱愛生活",這才是我們對待預測的正確態度,物料需要有基本的預測,同時需要同上下游基于基本預測做真誠溝通,不斷去修正我們的預測。
比如前面我舉例的A5車型預測,這個結果是在正常情況下的預測,但如果某月出現過一些疫情、促銷、新品上市等情況時候,這個模型計算出來的數據就不對了。這個時候可能需要采用多元非線性預測模型了,而這些"事件"不是物料計劃能預測或第一時間知道的,需要別的部門通知和多部門判斷。這個過程就是一個協同和管理的過程,你說它是不是體現了一個公司的供應鏈協同水平?


DeepSeek火出圈,AI和大模型將如何改變物流行業?
3125 閱讀
智航飛購完成天使輪融資
2555 閱讀
800美元不再免稅,T86清關作廢,跨境小包何去何從?
2184 閱讀凈利潤最高增長1210%、連虧7年、暴賺暴跌……物流企業最賺錢最虧錢的都有誰
2125 閱讀浙江科聰完成數千萬元A2輪融資
1955 閱讀AI紅利來襲!你準備好成為第一批AI物流企業了嗎?
1905 閱讀物流職場人性真相:鷹鴿博弈下的生存法則
1674 閱讀物流職場人性真相:馬斯洛需求的顛覆與掌控
1556 閱讀供應鏈可視化:從神話到現實的轉變之路
1392 閱讀Deepseek在倉庫規劃中的局限性:基于案例研究
1249 閱讀







粵公網安備 44030402005698號


 [羅戈導讀]利用excel做簡單的需求預測
[羅戈導讀]利用excel做簡單的需求預測