

 [羅戈導讀]數據倉庫技術依然有其廣泛的應用場景,我們應該根據業務的需求變化、用戶體驗的提升等角度對設計和技術選型進行調整和適應
[羅戈導讀]數據倉庫技術依然有其廣泛的應用場景,我們應該根據業務的需求變化、用戶體驗的提升等角度對設計和技術選型進行調整和適應
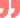


傳統的數據倉庫架構一般有由源系統、ODS、EDW、Data Mart幾部分組成。源系統就是業務系統、管理系統、辦公系統等等;ODS是操作數據存儲;EDW是企業級數據倉庫,Data Mart是數據集市。
1、源系統
業務系統、財務系統、OA系統、ERP系統等其實都是源系統,源系統的主要作用是就是產生數據。傳統行業大多是將這些數據存儲在Oracle和SQL Server上,互聯網行業則選擇開源數據庫(MySQL、NoSQL)的居多。
2、ODS
ODS全稱是Openrational Data Store,直譯過來就是操作數據存儲。在具體項目中往往被叫做中間庫或臨時庫。數據從源系統進入數據倉庫前一般會有一個中間層,就是ODS。
ODS有以下幾個特點:
整合異構的數據,數據都是先到ODS再到數據倉庫
轉移一部分業務系統細節查詢的功能,直接跨不同的關系型數據庫進行查詢有比較大的局限性
數據編碼標準化轉化
數據是動態的、可更新的,DW是靜態數據
ODS存儲當前或者近期的數據,DW存儲歷史性數據
ODS數據容量級別較小,DW的數據容量很大
上文提到的是傳統意義上對ODS的定義,而現在我們所理解的ODS已不再局限于此。現在ODS存儲的不單單是文本,還包括圖片和視頻。也就是說它變成了一個中間層,而涉及的技術也不僅僅是關系型數據庫,還有NoSQL或Redis這樣的類型數據庫。在前端采集數據量非常大的時候,關系型數據庫可能會頂不住壓力,但如果是Redis的話就可以將數據緩存在內存中,然后批量刷到關系庫中。
3、EDW介紹
EDW有如下特點:
面向主題:各個源系統之間在物理上往往是分離的,數據也是按照源系統服務的業務/流程進行組織,而數據倉庫中的數據是按照一定的主題域進行組織的。例如:用戶、組織、財務、事件、產品等主題。
集成性:數據倉庫中的數據是在對原有分散的數據庫數據進行抽取、清理的基礎上,再通過系統加工、匯總和整理后得到的,必須消除源數據中的不一致性,以保證數據倉庫內的信息在企業級是全局一致的。
相對穩定:數據倉庫的數據主要供企業決策分析之用,主要用來查詢,很少涉及修改和刪除(不提供修改和刪除的功能),通常情況下數據也不會輕易的被刷新(指進入DW的數據不會經常因為源系統的原因需要重新被刷新,如果有這個場景,要思考是否是設計上除了問題)。
反映歷史變化:數據倉庫中的數據通常包含歷史信息,記錄了企業從過去某一時點(如開始應用數據倉庫的時點)到目前的各個階段的信息,通過這些信息,可以對企業的發展歷程和未來趨勢做出定量分析和預測。
無論是傳統的的數據倉庫還是大數據時代的數據倉庫,EDW提供的功能并無太多差異。主要還是隨機查詢、固定報表以及數據挖掘,一般大數據層面更多的是偏向數據挖掘。
4、DM(Data Marts)介紹
數據集市一般是面向部門級業務(雖然很多時候都在說面向企業級,事實上在實施的時候往往面向的是部門級,這是傳統企業的一個很大的特征),是為了滿足他們的需求而建立的一種分析型環境。投資規模比較小,更關注在數據中構建復雜的業務規則來支持功能強大的分析。
現在有人認為數據集市的概念在大數據時代已經是過時了,其實這里面我認為還是有一定誤區。大數據時代也需要數據集市,只是數據集市中分析結果背后的邏輯有所變化,由因果關系逐步轉向了關聯關系。

我們認為傳統數倉仍然有非常大的應用場景,起碼是在大多數數據分析和商業BI上完全可用。在大多數場景下,最合理的做法是將DM替換成為現在更為流行、體驗更好的DV(數據可視化)產品。
為了適應大數據時代,傳統數據倉庫技術應該做如下的變化來更好的服務與企業數據分析的需求。
1、源系統設計
源系統設計本身并不屬于數據倉庫技術的一部分,但是源系統設計的優劣會直接影響數據倉庫實施的成本。最明顯的就是數據結構的不統一問題,這對后期數據抽取、清洗會帶來極大的成本,應該盡早的實行元數據管理。另外特別重要的一點是數據庫架構的規劃,要跳出某個具體的源系統,站在企業的角度對數據庫進行頂層架構設計。
2、ODS設計
中間庫通常被設計成數據庫集群而不是單機,每臺機器上會有多個MySQL或PG(PostgreSQL)實例。這樣就可以將數據分布到不同的機器上,形成一個接口庫成為集群。這里的集群并非傳統意義上的集群,中間庫應該是松散的MySQL集群、PG集群,數據量大的時候也可以選擇Redis集群。
3、EDW設計
數據倉庫的選擇在PostgreSQL、Greenplum和Hadoop中展開。對于在線交易系統選擇的肯定是PostgreSQL,而對于真正的數據倉庫就應該選擇Greenplum。
Greenplum體系結構
Greenplum由多個控制節點(master)和多個數據節點(segment Host)構成的集群。
之所以選擇Greenplum,第一是因為它的高性能。
而高性能首先體現在大表分布上,Greenplum中會將一個大表的數據均勻的分布到多個節點,為并行執行(并行計算)打下基礎。其次是并行執行,Greenplum的并行執行可以是外部表數據加載并行、查詢并行、索引的建立和使用并行、統計信息收集并行、表關聯并行等等。第三點是列式存儲和數據壓縮,如果常用的查詢只取表中少量字段,則列模式效率更高,如查詢需要取表中的大量字段,行模式效率更高。
選擇Greenplum的第二個原因是產品成熟度高。前面提到過Greenplum由多個節點組成,其實它的每個節點就是一個PostgreSQL。PostgreSQLy于1986年開始研發,1987年開發出第一個版本,1988年對外展出,可以說PG經過這么多年的發展已經是非常成熟的產品。
第三個原因是容災機制,Greenplum可以有兩個master節點,其中一個宕機的時候,另外一個會繼續接收訪問,并且這兩個節點的Catalog 和事務日志會保持實時同步。
第四個原因是線性擴展,Greenplum采用了通用的MPP并行處理架構,在 MPP架構中增加節點就可以線性提高系統的存儲容量和處理能力。Greenplum在擴展節點時操作簡單,在很短時間內就能完成數據的重新分布。Greenplum線性擴展支持為數據分析系統將來的拓展給予了技術上的保障,用戶可根據實施需要進行容量和性能的擴展。
最后一個原因是似曾相識的開發環境,由于Greenplum是基于PostgreSQL,在語法上和PG區別并不大,所以能夠讓傳統的Java開發人員平穩的過渡到Greenplum。
引入Hadoop
基于傳統的SQL查詢Greenplum可以輕松應對,但是在機器學習上就明顯不足,雖然Greenplum的MADlib支持機器學習,實際案例卻并不多見。因此要在EDW中引入Hadoop生態圈來滿足機器學習的需求。

上圖就是引入的hadoop生態圈,資源管理層使用Mesos和Yarm,分布式存儲層是HDPS,處理引擎層可以在MapReduce和Spark core間選擇。所以如果要做機器學習,其實有兩個選項,一是MapReduce加Mahout,二是Spark core加MLlib。而MapReduce在性能上有所不如,因此我們一般傾向于第二個方案。
最終數據經由Greenplum進入hadoop生態圈,然后根據開發能力以及應用選擇要存儲的地方。Greenplum在這里成為了機器學習的數據源,另外數據在進入hadoop以后,還是可以做基于SQL的查詢。
還有一點需要注意的是數據倉庫或者大數據平臺的計算結果一般都會被存儲到PG中,這是由于PG對大表的處理能力要強于MySQL。
數據倉庫技術依然有其廣泛的應用場景,我們應該根據業務的需求變化、用戶體驗的提升等角度對設計和技術選型進行調整和適應,而不是鼓吹概念,動則大數據,事實上有幾個企業里面擁有的數據真正屬于大數據?


DeepSeek火出圈,AI和大模型將如何改變物流行業?
3349 閱讀
800美元不再免稅,T86清關作廢,跨境小包何去何從?
2303 閱讀
凈利潤最高增長1210%、連虧7年、暴賺暴跌……物流企業最賺錢最虧錢的都有誰
2230 閱讀浙江科聰完成數千萬元A2輪融資
2137 閱讀AI紅利來襲!你準備好成為第一批AI物流企業了嗎?
2059 閱讀供應鏈可視化:從神話到現實的轉變之路
1469 閱讀運輸管理究竟管什么?
1343 閱讀Deepseek在倉庫規劃中的局限性:基于案例研究
1361 閱讀2024中國儲能電池TOP10出爐
1221 閱讀傳化智聯集成DeepSeek,深化AI大模型物流場景應用
1177 閱讀







粵公網安備 44030402005698號





















