
 [羅戈導讀]作者簡介:蔡智武 達達-京東到家大數據產品研發負責人,畢業于上海交通大學軟件學院,有多年數據倉庫和數據平臺系統建設及團隊管理經驗,2017年加入達達-京東到家,負責達達-京東到家大數據平臺整體規劃及產品研發工作。
[羅戈導讀]作者簡介:蔡智武 達達-京東到家大數據產品研發負責人,畢業于上海交通大學軟件學院,有多年數據倉庫和數據平臺系統建設及團隊管理經驗,2017年加入達達-京東到家,負責達達-京東到家大數據平臺整體規劃及產品研發工作。

達達-京東到家大數據平臺是根據公司業務持續快速成長,而規劃建設的一個可持續發展的平臺。在建設過程中我們借鑒了很多公司實施大數據平臺的經驗,并因地制宜構建了我們自己的實施策略,確保在大方向上不會走偏,并且每一年都會有重大變化和質的成長。
建設回顧

圖1 大數據平臺建設歷程
2016年——DRP平臺建設
這個階段數據倉庫還是Mysql,所有工作幾乎都是圍繞著短、平、快實現重要核心報表而開展,DRP的成功實施大大減少了分析師的工作量,給公司數據驅動換上了新的引擎。
2017年——工具專業化建設
這個階段數據倉庫已經換成Hive,因為mysql實在跑不動了,但是圍繞數據的一些工具都是空白的,分析師需要靠自己強大的記憶力來記住重要的元數據信息,業務部門也只能通過分析師獲取數據。在這一年,統一權限管理、元數據平臺、自助報表平臺、自助查詢平臺、數據交換平臺等工具應運而生,讓數據開放由設想變成實際可行。
2018年——應用體系化建設
由于歷史原因,這個時候整個平臺技術和應用體系其實還是挺參差不齊的,隨之而來的是系統穩定性比較差,DW值班人員經常需要起夜處理問題。這一年我們花大力氣重構了調度開發平臺、需求管理平臺,研發了數據質量監控系統,優化了權限體系、報表體系、查詢體系和數據交換體系,自研了E-SQL來解決HUE糟糕的使用體驗。同時,在數據服務和數據應用的建設上有了實際性的進展,各種數據開始通過數據服務中臺更加直接的影響業務,蒼穹系統也探索完成首個業務模塊。
2019年——資產生態化建設
2019年的主要方向是讓數據回歸資產本質,讓平臺擁有生態體系,讓應用實現產品驅動。我們會在數據倉庫建設上提煉行業數據資產;在計算引擎、存儲引擎、安全引擎及同步引擎上實現平臺生態化;在蒼穹系統建設上用更加產品化的思維幫助業務方發現問題并提供解決方案,提升大家的工作效率。
下面我將簡單介紹一下當前達達-京東到家大數據平臺的總體框架及主要組成部分的情況,并結合這些模塊的建設過程來闡述一下我們的實施策略。
總體框架

圖2 大數據平臺總體框架
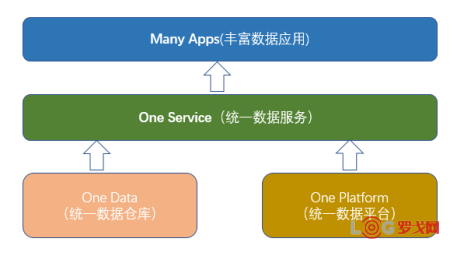
達達-京東到家大數據平臺作為同時支持公司達達物流和京東到家兩大事業群發展的基礎平臺,它由四部分組成:
統一的數據倉庫(One Data)、
統一的數據平臺(One Platform)、
統一的數據服務(One Service)、
豐富的數據應用(Many Apps)
如圖2所示,數據倉庫和數據平臺是基礎構件,數據服務是將數據開放出去的中軸,而數據應用是數據價值的最終體現者,整個大數據平臺建設致力于成為物流和零售行業數據驅動的標桿。

圖3 數據倉庫主題
統一的數據倉庫涉及物流和到家共計22個主題域,5000+的離線任務,120+的實時任務,數PB數據總量。在數據倉庫領域我們主要考慮的因素是覆蓋面、準確性及穩定性。
1、覆蓋面
數據覆蓋面是決定數據倉庫能否支持所有業務的基礎。想要完全覆蓋一個快速迭代和發展的業務,跟著業務系統走是行不通的,我們必須站在數據倉庫的視角來審視覆蓋的內容行業本質和用戶行為。如果把行業本質和用戶行為的內容都覆蓋了,那數據倉庫的覆蓋面就是完整的,需要解決的只是內容的豐富度而已。
從圖3看出,我們在達達物流及京東到家的數據主題域規劃上是分開的,但基本上大同小異。拿物流舉例:從行業本質來說,物流是將一個客戶的物品配送到另外一個客戶,會產生賬戶交易和財務結算;從用戶行為來說,為了做好物流這個事,我們需要有公司的組織保障、必要的市場營銷及良好的客戶售后服務,這些用戶行為將共同沉淀下來客戶端設備信息、位置信息及流量日志信息等。對到家來說,商品銷售和社區管理是零售不可或缺的重要組成部分,而這個不是物流的必要組成部分。
2、準確性
數據準確性是數據倉庫產生價值的根本。我們通過統一數據源、統一數據建模、集中ETL處理來規避了源頭的不一致、模型的二義性及處理邏輯的偏差,同時通過數據質量系統對核心指標做了監控預警,確保提供給出去的數據是準確無誤的。
3、穩定性
穩定性是衡量數據倉庫成熟度最重要的因素。只有覆蓋度和準確性,數據卻不能穩定交付是不行的,我們在穩定性提升的路上走得并不是太順利,很長一段時間這都是困擾我們的存在。為了保證穩定性,我們采用了事前預防、事中處理及事后復盤等多種策略,目前穩定性已經明顯好轉。幾個重要的事情說明一下:
① 數據源探測:離線抽數和推數任務成百上千,任何一個數據源的變動都會導致任務報錯。雖然與DBA保持了良好的溝通,但是通過人工預判總是會疏漏一些結構變化,每天定期做數據源探測則讓問題提前暴露,讓夜間抽數、推數報錯的概率大大降低。
② ETL優化解耦:集群的資源永遠是不夠用的,ETL性能優化及鏈路解耦是日常有空就得做的事情。好處很明顯,正常執行可以節省資源,異常重跑還可以節省時間。
③ 調度集群化:5000多個離線任務依賴調度系統運行,調度系統的高可用是非常核心的事情,任何一個調度環節出現單點故障,整個任務就會堵住,而大數據調度系統是個很復雜的系統,里面集成了很多任務類型的引擎,異常情況重新部署無論從資源協調還是部署時間上講都是不可行的。在調度未集群化之前,我們碰到過好幾次硬件故障導致只能等硬件搶修的情況,調度集群化之后我們在好幾次硬件宕機的情況下都安然無恙挺過。
④ 多重預警:期待不出問題是不可能的,當問題發生時及時的人工干預就是最后的兜底。我們設置了值班人員-任務開發者-ETL負責人-部門負責人四道防線來確保不會漏接異常預警;同時我們設置了進度預警機制,確認任務掛起不報錯的情況下能夠發現問題。
⑤ 運維專業化:Hadoop是個復雜的平臺,集群上了規模之后,運維專業化非常必要。我們嚴格拆分了實時集群和離線集群,任何一個配置變動都需要經過研發和運維的雙重審核。到目前為止,離線集群已經一年多沒有重啟了,相對于早期“重啟是解決一切疑難雜癥的最后良藥”,這已經是很大的進步了。

圖4 數據平臺模塊
統一的數據平臺涵蓋統一權限、開發平臺、數據采集、存儲引擎、計算引擎、資源管理和數據應用等組件的封裝和集成,如圖4所示。
① 統一權限平臺:權限管理是數據安全的基礎,Hadoop生態的權限管理做的非常一般,覆蓋不全、實施復雜及性能瓶頸的問題都會遇到,基于這個原因我們是自研了權限管理平臺,將hdfs、hive、presto、kafka、es、redis等離線和實時的數據對象做了統一管理和授權,同時與公司的ldap打通,保障用戶的使用體驗。
② 調度開發平臺:大數據平臺的調度開發平臺有別于線上的純調度系統,為了保障開發的體驗及運行的可控,我們集成了離線任務、近線任務、實時任務及任務預警等很多引擎,與git集成支持版本管理,同時保障多機房、多集群、負載均衡等任務分發機制,它已經是我們所有系統中最復雜的一個系統。目前配置2個主節點,每個機房或者每個集群同時配置2個以上的執行從節點,任何一個節點出現問題,其它多活節點都可以無縫托管這個問題節點的任務。
③ 數據源及采集:目前主流的關系型數據庫、Kafka、文本文件及非關系型數據庫等都支持配置化抽取。同時支持對MYSQL智能增量抽取,所有目標表及分區智能創建,大幅提升了ETL開發的工作效率。
④ 數據存儲:離線數據按天以上的頻度更新,以Hive、HDFS和Hbase存儲為主;近線數據按分鐘級的頻度更新,以Hive存儲為主,通過Presto提供查詢;實時數據根據應用的特性會存放在kafka、redis、hbase、es、druid及mysql中。
⑤ 資源管理:資源管理這塊沒有做太多了封裝,主要基于Yarn做了部分隊列的資源限制和權限限制。
⑥ 數據計算:實時計算引擎我們早期是基于Spark Streaming定制開發,目前已經基本遷移到Flink,并且基于開源的FLinkStreamSQL封裝了我們自己基于SQL的流式任務;近線計算引擎我們早期是基于Spark SQL定制開發,目前已經全部遷移到封裝好的基于SQL的Spark SQL引擎,并且同時支持Spark 1.6和Spark 2.2,與此同時我們所有的數據都支持以Presto引擎對用戶開放;離線計算引擎以Hive為主,我們正計劃通過封裝好的Spark SQL來逐步代替Hive引擎。
⑦ 數據應用:目前數據應用主要包括數據產品、查詢體系、算法應用、數據分析以及數據服務等這幾個方向。每個方向的用戶群體和使用場景都不太一樣,在設計應用架構時需要特別考慮這些因素,以精簡實用為主,避免周期長、大而全的建設,那樣研發試錯成本及應用實用化會是非常大的問題。

圖5 數據中臺服務
統一的數據服務整合了優質的數據倉庫和數據平臺資源,將數據以最短鏈路提供給數據應用、線上業務及開放平臺,如圖5所示,承擔的是數據中臺的職責,目標是讓內外部應用更加便捷的獲取到數據,加速數據的利用。統一數據服務是個邏輯上的概念,更側重于歸口建設、統一標準和集中管理,物理部署上我們是分開的。
① 中間庫服務:早期數據服務很簡單,就是提供中間庫服務,誰要數據去中間庫取。隨著應用的深入和數據量的增加,中間庫接口實現起來不僅費時費力,而且無法承載大數據量的交互。鑒于此,我們增加文件存儲服務和API服務。
② 存儲服務:通過把數據轉化成文本,存放到共享的sftp、http存儲及云盤等,需求方只要下載文件就可以解釋入庫,解決了大數據量交互的問題,但需求方還是需要開發對應的解釋入庫程序。
③ API服務:對于單次數據獲取量不大,讓數據需求方開發中間庫服務或者存儲服務接口,成本上比較高,而且同一接口不同需求方要重復建設,確實影響效率和浪費成本。鑒于此,通過數據部集中設計和開發api服務就應運而生,最開始我們每個api接口都需要定制開發,目前我們已經研發了基于配置化的通用服務,對redis、hbase、es、druid、mysql等存儲引擎的數據,通過配置一個簡單的SQL或者一些表和字段名就能很方便的開發出一個數據服務接口。

圖6 數據應用模塊
豐富的數據應用包括了BI自建應用、共享平臺應用以及共建業務應用等三部分,如圖6所示。
① BI自建應用:包含以蒼穹平臺為主的數據運營體系,以DRP和MiniReport為主的報表體系,以MyQuery和E-SQL為主的查詢體系,以調度開發為主的數據平臺體系,以及在移動端、H5端和微信端的各種定制數據產品應用。
② 共享平臺應用:在BI自建應用中My-Query、MiniReport作為共享平臺開放給了公司總部所有業務部門,調度開發平臺開放給了BI相關部門,這三個平臺支持用戶在上面構建屬于自己的應用或者任務;
③ 共建業務應用:包括了以平臺、商戶和品牌為主的CRM體系,以物流和到家算法為主的算法應用,以及圍繞訂單、配送、商戶、商品、營銷、廣告等業務的線上業務應用。在這些系統的建設過程中,數據中臺服務發揮了重大作用,將復雜的數據計算與整合環節全部交給數據部,業務部門只要專注于實現業務場景即可,實施效率得到了大幅度的提升。
對BI自建應用和共享平臺來說,使用頻次是考核這個系統是否成功的重要標準。基于研發資源狀況,我們并沒有追求應用的數量,而是爭取把每個應用質量做到最好。到目前為止,DRP、燈塔、MiniReport、MyQuery、E-SQL等系統的查詢頻次都達到了每天數千人次,為業務部門獲取數據提供了極為方便且多樣的選擇;同時,我們對DRP的官方報表做了嚴格篩選,到目前為止也沒超過300個,但共享平臺MiniReport和MyQuery上的自助報表和自助查詢數據都達到了600+,它們為業務探索期間的數據獲取及監控提供了簡單有效的解決方案,深受公司內廣大用戶喜歡。
總結展望
如果用一個人的成長期來比喻,那么達達-京東到家大數據平臺正好進入了青年期,在經過了懵懂的少年期之后,正在快速的向壯年期邁進,我們將會在數據賦能及技術縱深領域做出更多積極的探索。


“京東服務+”洗衣中央工廠招商、3C上門安裝/維修招商
2836 閱讀
嘉誠國際發布2024年年報:營收13.5億元,歸母凈利潤為2.05億元
2613 閱讀
深圳擬擴大試點物流、環衛功能型無人車運營,加速產業規模化進程(附編制說明等下載)
2552 閱讀這家老牌物流巨頭被收購,9億美元交易值不值?
2149 閱讀即將年營收超3000億元、迎來8.66萬名新員工,這家物流巨頭面臨最大風險
1653 閱讀京東外賣重點推廣39城
1428 閱讀京東,為外賣騎手繳納五險一金!
1272 閱讀普洛斯中國2024年表現穩健強勁,卓越運營助力新經濟勢能攀升
1212 閱讀豐巢與菜鳥破壁合作 菜鳥寄件可選“到柜寄”默認順豐承運
1103 閱讀菜鳥出席世界郵政和快遞美洲會議,國際物流服務受全球市場認可
1084 閱讀







粵公網安備 44030402005698號




















