









7777788888精準(zhǔn)一肖,澳門一肖一特一一中,2025新澳正版資料最新,新澳今年晚上9:30開(kāi),管家婆一獎(jiǎng)一特一中是什么獎(jiǎng),,澳門管家婆100準(zhǔn)確,2025新澳門歷史記錄走勢(shì),澳門一肖一碼一中管家,澳門一碼一肖一特一中管家,新澳2025今晚開(kāi)彩資料,澳門管家婆100準(zhǔn)確,2025新澳門天天開(kāi)好彩,新澳門好彩免費(fèi),2025新澳門天天開(kāi)好彩/精選解析解釋落,新2025年澳門天天開(kāi)好彩,新澳門管家婆一特一中,2025最新免費(fèi)資料大全,7777788888新版跑狗圖,王中王72396cm資料查詢20碼,澳門管家婆100%精準(zhǔn)香港,2025年正版資料免費(fèi)大全最新版本,新澳門2025最新款免費(fèi),2025新澳門天天開(kāi)好彩.,澳門一肖一特一一中管家,新澳門4949最新開(kāi)獎(jiǎng)記錄,澳門今晚開(kāi)精準(zhǔn)四不像,2025新澳門天天開(kāi)好彩大全,新澳今晚9點(diǎn)30分,2025年澳門精準(zhǔn)免費(fèi)大全,澳門管家婆一特一中,2025澳門正版免費(fèi)精準(zhǔn)大全367期,今晚必中必開(kāi)一肖,9點(diǎn)30開(kāi)特馬結(jié)果,2025最精準(zhǔn)原料免費(fèi)大全,新奧精準(zhǔn)免費(fèi)提供港澳彩,澳門一碼一碼100準(zhǔn)確今晚,2025新奧天天開(kāi)好彩,新奧天天開(kāi)獎(jiǎng)資料大全600tkm,7777788888管家精準(zhǔn)管家婆免費(fèi)香港免費(fèi),2025精準(zhǔn)免費(fèi)資料查詢,2025新澳門天天開(kāi)獎(jiǎng)記錄,新澳門天天彩免費(fèi)提供,澳門一碼一特一中管家,管家婆一獎(jiǎng)一特一中,2025澳門天天免費(fèi)大全,2025澳門特馬,2025年澳門天天有好彩,澳門一碼一碼100準(zhǔn)確 官方,新澳門2025年正版免費(fèi)公開(kāi),新奧2025最新資料大全,澳門一碼一特一中

港彩高手出版精料
澳門精華區(qū)
香港精華區(qū)
- 185期:【貼身侍從】必中雙波 已公開(kāi)
- 185期:【過(guò)路友人】一碼中特 已公開(kāi)
- 185期:【熬出頭兒】絕殺兩肖 已公開(kāi)
- 185期:【匆匆一見(jiàn)】穩(wěn)殺5碼 已公開(kāi)
- 185期:【風(fēng)塵滿身】絕殺①尾 已公開(kāi)
- 185期:【秋冬冗長(zhǎng)】禁二合數(shù) 已公開(kāi)
- 185期:【三分酒意】絕殺一頭 已公開(kāi)
- 185期:【最愛(ài)自己】必出24碼 已公開(kāi)
- 185期:【貓三狗四】絕殺一段 已公開(kāi)
- 185期:【白衫學(xué)長(zhǎng)】絕殺一肖 已公開(kāi)
- 185期:【滿目河山】雙波中 已公開(kāi)
- 185期:【寥若星辰】特碼3行 已公開(kāi)
- 185期:【凡間來(lái)客】七尾中特 已公開(kāi)
- 185期:【川島出逃】雙波中特 已公開(kāi)
- 185期:【一吻成癮】實(shí)力五肖 已公開(kāi)
- 185期:【初心依舊】絕殺四肖 已公開(kāi)
- 185期:【真知灼見(jiàn)】7肖中特 已公開(kāi)
- 185期:【四虎歸山】特碼單雙 已公開(kāi)
- 185期:【夜晚歸客】八肖選 已公開(kāi)
- 185期:【夏日奇遇】穩(wěn)殺二尾 已公開(kāi)
- 185期:【感慨人生】平特一肖 已公開(kāi)
- 185期:【回憶往事】男女中特 已公開(kāi)
- 185期:【瘋狂一夜】單雙中特 已公開(kāi)
- 185期:【道士出山】絕殺二肖 已公開(kāi)
- 185期:【相逢一笑】六肖中特 已公開(kāi)
- 185期:【兩只老虎】絕殺半波 已公開(kāi)
- 185期:【無(wú)地自容】絕殺三肖 已公開(kāi)
- 185期:【涼亭相遇】六肖中 已公開(kāi)
- 185期:【我本閑涼】穩(wěn)殺12碼 已公開(kāi)
- 185期:【興趣部落】必中波色 已公開(kāi)
【管家婆一句話】

【六肖十八碼】
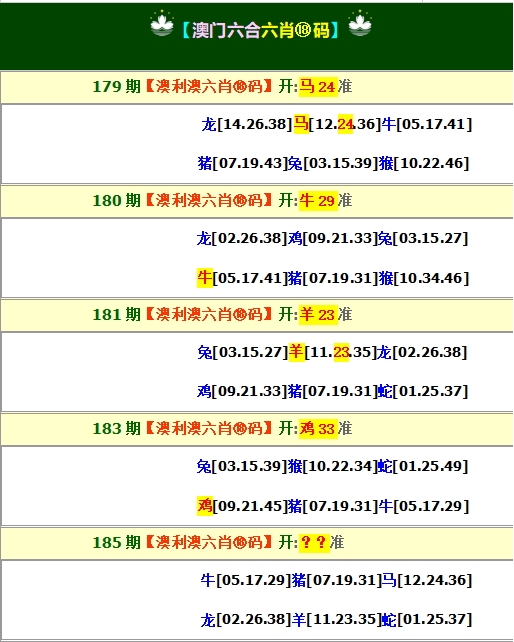
澳門正版資料免費(fèi)資料大全
- 殺料專區(qū)
- 獨(dú)家資料
- 獨(dú)家九肖
- 高手九肖
- 澳門六肖
- 澳門三肖
- 云楚官人
- 富奇秦準(zhǔn)
- 竹影梅花
- 西門慶料
- 皇帝猛料
- 旺角傳真
- 福星金牌
- 官方獨(dú)家
- 貴賓準(zhǔn)料
- 旺角好料
- 發(fā)財(cái)精料
- 創(chuàng)富好料
- 水果高手
- 澳門中彩
- 澳門來(lái)料
- 王中王料
- 六合財(cái)神
- 六合皇料
- 葡京賭俠
- 大刀皇料
- 四柱預(yù)測(cè)
- 東方心經(jīng)
- 特碼玄機(jī)
- 小龍人料
- 水果奶奶
- 澳門高手
- 心水資料
- 寶寶高手
- 18點(diǎn)來(lái)料
- 澳門好彩
- 劉伯溫料
- 官方供料
- 天下精英
- 金明世家
- 澳門官方
- 彩券公司
- 鳳凰馬經(jīng)
- 各壇精料
- 特區(qū)天順
- 博發(fā)世家
- 高手殺料
- 藍(lán)月亮料
- 十虎權(quán)威
- 彩壇至尊
- 傳真內(nèi)幕
- 任我發(fā)料
- 澳門賭圣
- 鎮(zhèn)壇之寶
- 精料賭圣
- 彩票心水
- 曾氏集團(tuán)
- 白姐信息
- 曾女士料
- 滿堂紅網(wǎng)
- 彩票贏家
- 澳門原創(chuàng)
- 黃大仙料
- 原創(chuàng)猛料
- 各壇高手
- 高手猛料
- 外站精料
- 平肖平碼
- 澳門彩票
- 馬會(huì)絕殺
- 金多寶網(wǎng)
- 鬼谷子網(wǎng)
- 管家婆網(wǎng)
- 曾道原創(chuàng)
- 白姐最準(zhǔn)
- 賽馬會(huì)料
[]
友情鏈接:百度
"*"是廣告/外鏈,所有內(nèi)容均轉(zhuǎn)載自互聯(lián)網(wǎng),內(nèi)容與本站無(wú)關(guān)!
謹(jǐn)供娛樂(lè)參考!嚴(yán)禁轉(zhuǎn)載、盜鏈等一切不法行為!
Copyright @ 2005 - 2024 澳門官方 ICP備案號(hào)